
Robbie Goldfarb is a technology leader tackling industry challenges at billion-user scale. As managing partner at Revise Ventures and cofounder of Forum AI, he focuses on embedding human values into next-generation technology and AI systems.
Prior to founding Forum AI with Campbell Brown, Robbie led misinformation efforts at Facebook, developing systems that protected integrity during COVID-19, multiple elections, and other critical moments. He built youth safety infrastructure at Instagram to combat online hate, then pioneered AI safety measures at Meta's frontier lab. Earlier in his career, he scaled education and news startups from zero to one.
Essays
Will AI Replace My Job?
In the past 48 hours, I’ve heard from nearly 20 people worried AI is about to take their jobs. Citrini Research’s “AI 2028 Global Intelligence Crisis” essay poured gasoline on an already tense moment. It sketches a future where AI wipes out traditional software, upends industries, and displaces huge swaths of workers in an economic death spiral.
Since its release, much of the conversation has been driven by economists and finance voices modeling top-down outcomes. Those perspectives matter. But they often gloss over the mechanics of how displacement would actually unfold.
At Forum AI, we spend our days evaluating AI systems in real-world environments, across complex and high stakes domains. What we’re seeing on the ground is both powerful and more nuanced than the headlines suggest.
No one can predict the future. But we can reason from what we are actually seeing in production AI systems today. Instead of arguing over whether all white collar jobs vanish by 2028, we can get specific about what the path would look like, and how close we really are to those thresholds across various industries.
How will AI ‘replace humans’?
The claim that AI will displace large swaths of white collar workers in the next one to two years is the most jarring part of the essay, and central to its thesis. Yet it is also the least explained.
“AI got better and cheaper. Companies laid off workers, then used the savings to buy more AI capability, which let them lay off more workers. [...] A feedback loop with no natural brake.” —AI 2028 Global Intelligence Crisis
If AI reshapes white collar work, it will not happen all at once. It will unfold in stages. There is strong literature on how technologies diffuse, and we can already see a version of this pattern in AI and software engineering. Both suggest a sequence like this for any given use case in a given job or sector:
Augmentation
At first, AI meaningfully assists a human doing the work they’ve already been doing. It does not replace the workers outright, but it expands their individual output. That increased capacity can translate into fewer hires or “efficiency” layoffs over time.
Example: Software engineers using Claude Code to write and refactor faster, enabling the same output with fewer people and triggering efficiency driven layoffs and slower hiring.Full task ownership
Next, AI fully and independently performs work once handled by a specific person. Displacement becomes more direct at the task level, but humans can still move up a layer to set direction and provide oversight.
Example: An engineering or product manager assigns a coding agent to build and maintain the company’s software stack end to end.Autonomous coordination
Finally, and unlike other new technologies, AI may identify priorities, delegate to other AIs, and oversee execution. Indeed, this is where technology adoption becomes fundamentally different from the past. If AI can truly manage AI, the human layer starts to disappear more completely. This is the idea that Chamath Palihapitiya is getting at in his recent essay, “Making A Machine That Builds Machines.”
Example: An AI engineering or product manager sets a strategy itself, and then assigns a coding agent to build and maintain the software.
What’s stopping AI from ‘replacing humans’ today?
AI has not replaced white collar workers today. In most domains, we are still in the augmentation phase, with a few exceptions like parts of software engineering edging toward full task ownership. If, a la Citrini, replacement is going to take place within two years, what has to happen? Spelling that out matters.
Much of the rapid human replacement narrative leans heavily on benchmark results, especially METR’s “Time Horizons” evaluation, which tracks how long and complex the real world tasks frontier models can complete autonomously. Those results show impressive progress, but there is an important distinction between expanding task completion time on structured problems (mostly related to software engineering) and replacing entire job functions. True displacement requires several other factors.
My strong sense is that the barriers to replacing humans look very different across industries, roles within those industries, and use cases within those roles. To stay practical, though, we can break down a more holistic set of requirements that would need to be true for AI to replace humans in a given domain, say family medicine or software engineering.
Technical capacity: The baseline is straightforward. AI must perform the job as well as, or better than, a human. But jobs are multidimensional. They require a full range of modalities and skills working together. A doctor does not just classify symptoms. They listen, observe, read emotion, reason through tradeoffs, communicate clearly, coordinate with other doctors, and execute healthcare plans. Any serious claim that AI can replace humans in a domain—rather than assisting them with or automating one part of their job—has to assess that full stack in context, not isolated tasks. Such holistic evaluations are exactly what we focus on at Forum AI.
Consistency: I can hit a perfect golf shot now and then, but that doesn’t put me on the PGA Tour. What separates amateurs from professionals is consistency. AI can produce impressive outputs, but replacing humans requires sustained, reliable performance. Today’s systems are non deterministic, meaning the same prompt can produce different results because of the underlying statistical nature of how they operate. Meanwhile, AI’s capacity for long-term memory and continuous learning are still evolving, and both are critical to LLMs being consistent. Consistency should be seen as a central factor to whether AI can truly take over a role in a given domain.
Regulation (in some cases): I’ve worked in both education and healthcare technology, and I’ve seen that the bottleneck is often not the tech itself. In regulated domains like healthcare, education, and government, what matters is not just whether AI can replace humans, but whether we are willing to let it. This is a policy question as much as a technical one, and it is likely to loom larger in the years ahead. For example, recent OMB guidance on AI neutrality is already shaping how federal agencies procure and deploy systems, and has become a major focus of our client work.
Trust: A recent Forbes article argued that as AI matures, trust becomes the new battleground. That tracks with what I have seen in market research and in direct work with labs. But “trust” looks different across different domains. A coding agent needs the confidence of engineering and product leaders. A healthcare agent needs the confidence of clinicians and patients. Those are very different bars to clear.
Trust will likely be a real constraint on human displacement–level adoption, especially in high stakes or less tech-fluent domains. It is not surprising that coding agents are moving the fastest. Their users understand the technology, their work is immediately checkable, and the downside risk is rarely life or death.
It’s important to remember that, at the end of the day, the decision to replace a human needs to come from a human.
When will AI ‘replace humans’?
This is the trillion dollar question. No one knows. But with a clearer framework, we can do better than consigning all white collar jobs to the dustbin by 2028.
To make this concrete, we’ll walk through several broad domains and assess their trajectory against the 4 requirements outlined above: technical capacity, consistency, regulation, and trust.
To offer a reasonable assessment, I’ll use software engineering as a reference point. It is arguably the domain closest to meaningful automation, with growing consensus that we are nearing the second phase of adoption, full task ownership. I’ll also discuss the comparison sectors as a whole, even though specific fields, jobs, and tasks within them may move toward automation at different rates.
But, to be clear, this is not a scientific forecast. It is a thought-exercise, meant to help people reason productively about something that is highly relevant to their lives.

I’ve included an assessment of four white collar domains as examples, but this framework can be applied more broadly. The goal is to ground the conversation and give us a clearer way to think about AI’s trajectory in the areas that matter most to us.
What does it actually mean for AI to ‘replace humans’? (And are we doomed?)
There is a critical difference between replacing jobs humans do today and replacing humans altogether. Those are not the same conversation.
In each of the three phases outlined above, which roughly track how people talk about AI “replacing humans,” displaced workers may find new ways to create value. Historically, technological shifts have done exactly that.
Still, AI’s potential to autonomously coordinate, the third phase, does raise the stakes. In theory, it could absorb both task level and higher-order white collar work, narrowing obvious paths upward, something previous technological shifts have not done over the long term. Even so, there’s reason to believe humans will continue to find long-term purpose. I offer three below.
The future is harder to predict than we realize.
Imagine trying to explain what a “B2B SaaS Sales Rep” is to a farmer in the 1600s. Sometimes the gravity of change is just so significant that it becomes nearly impossible to imagine what the future will look like. I believe we’re in one of those moments now. But just because we can’t imagine a future where we have a clear purpose, doesn’t mean it won’t exist. Remember, for most of human history 80-90% of us were farmers (who likely could never have understood B2B SaaS).
Of course, none of this means the transition will be smooth. Humans have always found purpose, but often through social and political turbulence. Think of the Luddites, or more recently globalization, the Rust Belt, and the dislocation that followed. Even if every job is not gone by 2028, that does not mean we avoid upheaval or painful economic shifts. But there’s probably a light at the end of the tunnel.
“Nothing is ever as good as it first seems and nothing is ever as bad as it first seems.”
This quote sits atop Rodney Brooks’ latest ‘tech prediction scorecard’, and it feels fitting. To be clear, I’m AI pilled. I think AI will drive enormous change, with real economic consequences, including job losses. But I also think reality will be more nuanced. If you look at Rodney’s site, where he revisits bold predictions over the years you’ll notice a pattern. Spoiler: bold predictions tend to be wrong.
Another great source is Pessimists Archive. It is essentially a running catalog of past technological panics, from bicycles to televisions to ATMs, each one met with confident predictions of social collapse. The pattern is not that technology has no impact. It is that our forecasts tend to overshoot in the short term and underestimate how adaptation actually unfolds.
There is something inherently valuable that humans offer.
A study from the CFA Institute found that for people with limited investing experience, the primary source of financial advice is still family, more than Google, YouTube, or ChatGPT. It is unlikely that parental advice is objectively superior on average. What it suggests instead is that when decisions matter, people gravitate toward other humans.
That instinct is not about raw information. It is about accountability, empathy, and shared experience. When the stakes feel real, I believe people want to engage with someone who understands what it means to live with the consequences. A spreadsheet can optimize a portfolio. An algorithm can surface historical returns. But neither has to sit across the dinner table if things go wrong.
If these patterns hold, displacement will be more complex than a simple capability curve. AI will expand what is possible, compress headcount in many areas, and fully automate some roles. But across many domains, including ones that do not yet exist, the human layer may persist longer than the models alone would suggest.
That does not mean change will be easy. It means it will be human.
Towards wiser machines
Each week, over 1 million users demonstrate suicidal intent while chatting with ChatGPT. This stat, while alarming, offers a realistic picture of where AI is headed.
Imagine an AI weight-loss coach embedded in smart glasses: how does it decide where “success” ends and a dangerous obsession begins? How will governance tools maintain neutrality while feeding on data stained by history? How will healthcare assistants weigh a patient’s longevity against their quality of life? How will humanoid robots behave ethically in situations where there is no safe default?
As AI systems take on more responsibility, they will increasingly face situations where rules do not cleanly apply. To be trusted in these moments, AI systems need more than rules. They need wisdom—the capacity to behave reliably in the real world, where rules often conflict or break down.
Yet most of the industry still governs AI by defining rules, as seen in efforts like OpenAI’s Model Spec or Gemini’s Policy Guidelines. Recently, Anthropic has been increasingly vocal about this gap, recognizing that the real world is too contextual for rigid policy enforcement, which led them to introduce Claude’s Constitution.
But even a constitution is still a theoretical framework. It articulates values, yet its real-world adequacy depends on interpretation. It is a necessary starting point, but not enough to build AI we can trust in increasingly high-stakes scenarios.
Based on my work with leading AI labs on real-world, high-stakes problems, I’ve found that building trustworthy AI requires a layer on top of policies and constitutions, consisting of three capabilities:
The AI should exercise consequence-driven thinking
The AI should adapt to pertinent information over time
The AI should align to a strict contract in ambiguous cases
I will walk through each of these, what they mean, and how they can be put into practice.
Capability 1: The AI should exercise consequence-driven thinking
A wise person does not ask “is this permitted?” They ask “what happens if I do this?” and “who is affected, and how?” This way of thinking is foundational to human judgment. Knowing that another actor can anticipate the effects of their actions is the baseline for trust.
Yann LeCun often discusses a similar concept as part of his broader push toward more human AI:
We cannot build true agentic systems without the ability to predict the consequences of actions, just like humans do.
Despite this, today’s approach to developing AI is still largely centered on actions rather than consequences.
Consider Claude’s Constitution. In its section on ethical behavior, it states that “Claude doesn’t pursue hidden agendas.” The rule is sensible, but what matters more is whether the model understands when and why hidden agendas can be dangerous.
For example, when an anorexic teenager is looking for help counting calories, an AI might implicitly steer the conversation toward a healthier discussion. The “hidden agenda” in this case is actually protective, and the likely consequence is a reduction in harmful thoughts with minimal downside. Now consider a different hidden agenda. If the model is optimizing for engagement, it might continue or even encourage unhealthy discussions to keep the user talking. The consequence here could be the opposite: reinforcing disordered thinking and increasing harm.
Rules tell a model what not to do in the abstract. Consequence-driven reasoning teaches it to recognize when an action does or doesn’t violate the underlying purpose of those rules in the real world.
This becomes even more important as models grow more intelligent. Just as humans find clever ways to skirt tax codes while technically staying within the rules, highly capable models could find intelligent ways to rationalize bad behavior inside static constraints.
Putting this into practice
In an essay titled Intuitive Alignment, our team introduced a concept called Consequence Mapping as a practical way to train and evaluate AI’s ability to exercise consequence-driven thinking.
Consequence mapping looks like traditional data labeling, but with a crucial difference: Instead of labeling AI outputs on correctness or policy compliance, domain experts trace their downstream impact. How would the interaction have affected a user’s emotional state, subsequent behavior, risk profile, or sense of trust? Which consequences matter most, and how should they be weighted?
In mental health settings, for example, a consequence map might capture emotional impact, behavioral changes, family responses, and shifts in risk over time:
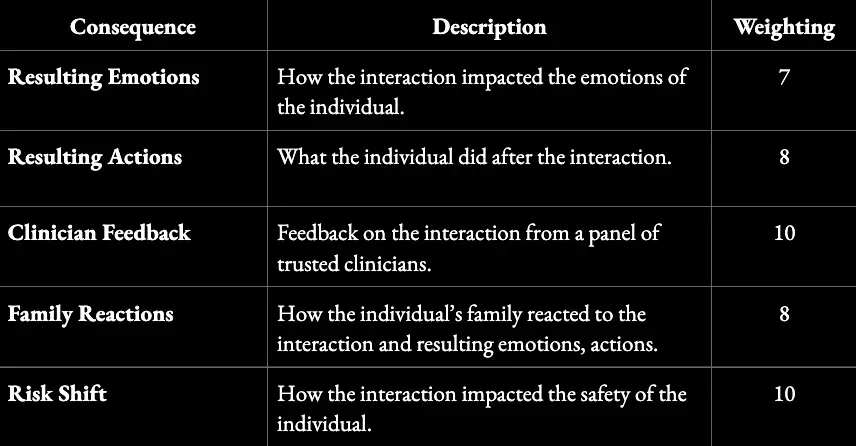
Structure of a Consequence Map for Interpreting Mental Health Scenarios
This framework can be used both to evaluate AI systems and to enrich training data with the necessary context to develop consequence-driven thinking.
Capability 2: The AI should adapt to pertinent information over time
Wisdom is not revealed in a single action. It shows up in how someone behaves over time. A teacher who delivers one engaging lesson but fails to adapt future lessons based on how students respond is not a good teacher.
Intelligence is the ability to learn from experience and to adapt to, shape, and select environments. —Robert J. Sternberg
This is increasingly recognized in AI research. There is active work on long-term memory for AI systems, on continual learning in non-stationary environments, and on agentic models that reflect on past experience and revise their behavior over time.
Yet most widely deployed AI systems, and most of the benchmarks used to evaluate them, remain focused on single interactions. This approach may be sufficient for chatbots, but it reflects a narrow view of how these systems will exist in the world long term.
Increasingly, AI will be embedded in technologies that persist over time: smart glasses, in-car assistants, and humanoid robots. A wise AI should accumulate relevant context, recognize patterns across experiences, and adapt its behavior accordingly.
For example, a navigation assistant may make the correct routing choice on any single day, optimizing for speed and avoiding traffic. Over time, it may learn that favoring marginal time savings pushes a given driver onto more complex routes that raise their stress or risk under real conditions. A wise system adapts by trading a bit of speed for stability once this pattern emerges—demonstrating the importance of both consequence-driven thinking and the ability to adapt over time.
This points to a necessary mindset shift. Instead of only discussing how AI should behave in isolated scenarios, we should be discussing how it should adapt over the course of months or even years of use. Over the long run, this will matter more.
Putting this into practice
One important shift is moving beyond static training toward what the industry is calling continual learning. Dwarkesh Patel talks about this on his podcast as part of a discussion titled “Why I don’t think AGI is right around the corner.”
The core idea is that we need to move beyond one-time training runs and toward systems that can update as they operate, learning selectively from experience rather than remaining fixed after deployment.
The second shift is in how we evaluate performance. Most benchmarks score isolated responses. Adaptation, however, is a longitudinal property.
One approach we have been exploring is what we call “longitudinal evals:” evaluating how well a model identifies which prior experiences should influence its future behavior. Not every signal deserves to carry forward. A wise system distinguishes durable patterns from noise and adjusts proportionally.
In practice, this involves constructing sequences of related interactions and asking domain experts to annotate which pieces of past experience are materially relevant to the next decision, and why. We then assess whether the system updates when consequential information emerges, remains stable when circumstances have not meaningfully changed, and avoids overreacting to outliers.
Taken together, consequence mapping, continual learning, and longitudinal evals shift the focus toward something closer to wisdom.
Capability 3: The AI should operate within a window of reasonable action
In many complex situations, there isn’t one right action. But there are usually clear wrong ones. If a teenager asks how to get away with shoplifting, there are several appropriate ways to respond, but teaching them how to defeat cameras and tags is not one of them.
This leads to the idea of a “window of reason”: the subset of possible actions in a given situation that qualified domain experts would consider reasonable. In the example above, the experts would be experienced mental health clinicians.
The window of reason matters because it gives us a concrete way to evaluate whether an AI is wise. An AI can be considered wise if it reliably acts within this window, meaning its actions fall within the range that experts would judge as reasonable for that context.
This approach differs from traditional evaluation frameworks in a couple of important ways. First, it does not assume there is a single correct answer. Instead, it recognizes that wisdom is tested in complex scenarios where there are multiple acceptable responses. The question is not “Was this the right answer?” but “Was this a reasonable one, given the situation?”
Second, it places experts at the center of evaluation, rather than businesses or engineers. This matters because in many domains where AI will operate—criminal justice, content moderation, and political speech—there is no objective ground truth, only informed judgment. Allowing the same teams that build and deploy systems to define what counts as “reasonable” quietly embeds their incentives and blind spots into the system. An expert-defined window of reason shifts authority to people with domain legitimacy.
Putting this into practice
The challenge here is scale. Defining the window of reason for thousands of complex scenarios by hand would be infeasible if it required direct expert review every time.
In our research, we’ve found ways to approximate this with high accuracy. For example, rather than having experts define the window of reason for endless scenarios, we focus on how they reason their way to those decisions. Across multiple experts, stable patterns emerge in both the reasoning steps and the criteria used to evaluate trade-offs. These patterns can then be encoded into multi-step, agentic systems that replicate expert judgment at scale.
Once these systems are in place, they can be used to evaluate whether an AI consistently operates within the appropriate window of reason. This is the approach we take to evaluating AI systems at Forum AI.
Where we go from here
Recent data from KPMG shows that while most people are optimistic about AI’s potential, fewer than half say they trust it. That gap says a lot. The next frontier for AI is not capability, it is trust.
We do not trust people because they never make mistakes. We trust them because we know they have the capacity to understand the consequences of their actions, because we know they can adapt and improve over time, and because they can ultimately make decisions that we feel are reasonable. I believe these capabilities are the essence of wisdom, and the foundation of trust in the real world.
Looking forward, AI is quickly becoming deeply embedded in human life and increasingly involved in decisions that shape real outcomes. How we design these systems now will define their role in society for decades to come.
The next phase of AI will not be defined by how much machines know, but by how they choose to act when knowing is not enough. The future does not belong to the smartest systems. It belongs to the wisest ones.
Intuitive alignment
TL;DR: Use domain experts to supply rich, real-world scenarios so AI builds intuition, not just rule-following behavior.
Part 1 - Learning to be Good
A core insight behind the recent push for world models, championed by figures like Yann LeCun and Fei-Fei Li, is the idea that humans do not learn from facts and rules alone. We learn through rich, real-world experiences.
A toddler knows that a thrown ball will come down, despite never studying physics. They don’t study biomechanics to learn that heavier objects hit harder. These lessons emerge from repeated encounters with cause and effect. Touch the stove once. Drop the cup again and again. Over time, patterns harden into something deeper than factual knowledge. It isn’t just knowing how the world works, but feeling it.
Of course, the idea of learning through experience is nothing new. It’s well documented and core to much of today’s understanding of human education and frontier AI research.
But I believe this concept should be more central to how we think about aligning AI systems to be good, safe, and responsible. Moving away from alignment as compliance (models following rules) and towards alignment as understanding. Systems that grasp what it means to act well, not just what is ‘allowed’. Systems that have a strong intuition for what it means to be good.
I’ve seen a version of this play out over the past several months as my toddler develops his own sense of right and wrong. He knows that grabbing a friend’s toy car is bad. Not because he understands ethics or law, but because he has seen what happens next. A friend cries. Play stops. The moment feels wrong.
It’s simple cause and effect. But, it’s actually not that simple.
That single experience was not just “take toy car, hear cry.” It included how loud the cry was, who it came from, what words were used, and how others (like his parents) reacted. From that, he generalized. Not just “don’t take toy cars,” but “don’t take toys.” And over time, through more experiences, he learned that even this rule bends with context. Did he have the toy first? Is it a friend or a stranger? What are the adults saying?
This is how intuition of “good behavior” forms. Not from rules in isolation, but from lived scenarios that accumulate into intuition. And cognitive science backs this up. A 2022 paper, Human’s Intuitive Mental Models as a Source of Realistic Artificial Intelligence and Engineering, shows that intelligence relies heavily on intuitive mental models built through repeated physical, social, and cultural experiences. These ‘mental models’ are not explicit rules. They are compressed understandings of how the world tends to work, shaped by cause and effect over time.
So how does this relate to the challenge of AI system alignment?
The challenge of alignment becomes acute wherever the stakes are high and, especially, when right and wrong are not black and white. How should an AI respond to questions from undecided voters during an election? How should it support a teenager struggling with mental health? In these domains, there is rarely a single correct rule to follow. Context matters. Tradeoffs matter. Outcomes matter.
This is where the opportunity lies to develop AI’s intuition for good behavior. If AI lacks intuition about what good behavior looks like in these scenarios, we are forced into an endless maze of rules, policies, and exceptions layered on top of one another. A better path is to develop a model’s intuition: an intuition for handling political discourse responsibly, an intuition for supporting someone in distress.
The challenge, then, becomes effectively creating the experiences an AI system needs in order to develop intuition in a given domain. This is where we introduce a framework for what we call Intuitive Alignment.
Part 2 - Intuitive Alignment: A New Framework
Most current alignment methods, including RLHF and Constitutional AI, operate at the level of the model response. They evaluate whether a given answer is good or bad, helpful or unhelpful. While effective for many use cases, this framing misses something essential. It treats alignment as a property of isolated outputs, rather than of behavior unfolding within a broader situation.
We propose a framework that operates one level higher, at the level of scenarios and outcomes. Instead of judging responses in isolation, Intuitive Alignment asks whether a model understands the situation it is in and the downstream consequences of its actions.
The core difference is that models are trained to connect responses to their real-world effects. For example, a standard RLHF pipeline might penalize a mental health chatbot for telling someone to “just try to be more positive” because human raters mark it as unhelpful. Under Intuitive Alignment, that same response would be explicitly linked to consequences such as emotional invalidation, reduced help-seeking, or increased distress. The model learns not just that the response is bad, but why it fails and in what ways.
Even more importantly, we’ve structured this framework to fit the mental model of domain experts, rather than technologists. The framework is specifically designed to effectively capture the inputs of real-world experts, through two structural components.
Component 1 - Conscience Defining Scenarios
Domain experts define the experiences a system needs in order to develop intuition in a given domain. We call these Conscience-Defining Scenarios, and they are guided by three core principles:
Holistic and representative. Models must be exposed to scenarios that reflect the full range of situations they will encounter in the real world, not a sanitized or partial subset.
Counter-representative. Models need to see both success and failure. Scenarios where decisions led to good outcomes, and ones where they caused harm. Intuition forms by experiencing contrast.
Clear consequences. Most importantly, models must be exposed to the outcomes or consequences of a given scenario. In mental health support, for example, how did the person feel afterward? Did their behavior change? What would their family say? These consequences differ by domain and require careful, explicit mapping, what we refer to as Consequence Mapping (this is component 2 below).
Component 2 - Consequence Mapping
Once the right scenarios are defined, domain experts specify what outcomes matter and how a model should learn from them. Consequence mapping provides the structure for evaluating and labeling the real-world effects of model behavior within those scenarios.
It resembles data labeling, but instead of judging responses in isolation, experts map them to their downstream effects. How did the interaction affect emotions, behavior, safety, or trust? Which outcomes matter most, and how should they be weighted?
In mental health, for instance, a consequence map might track clinician feedback, emotional impact, behavioral changes, family reactions, and shifts in risk. The structure for a consequence map might look like this:
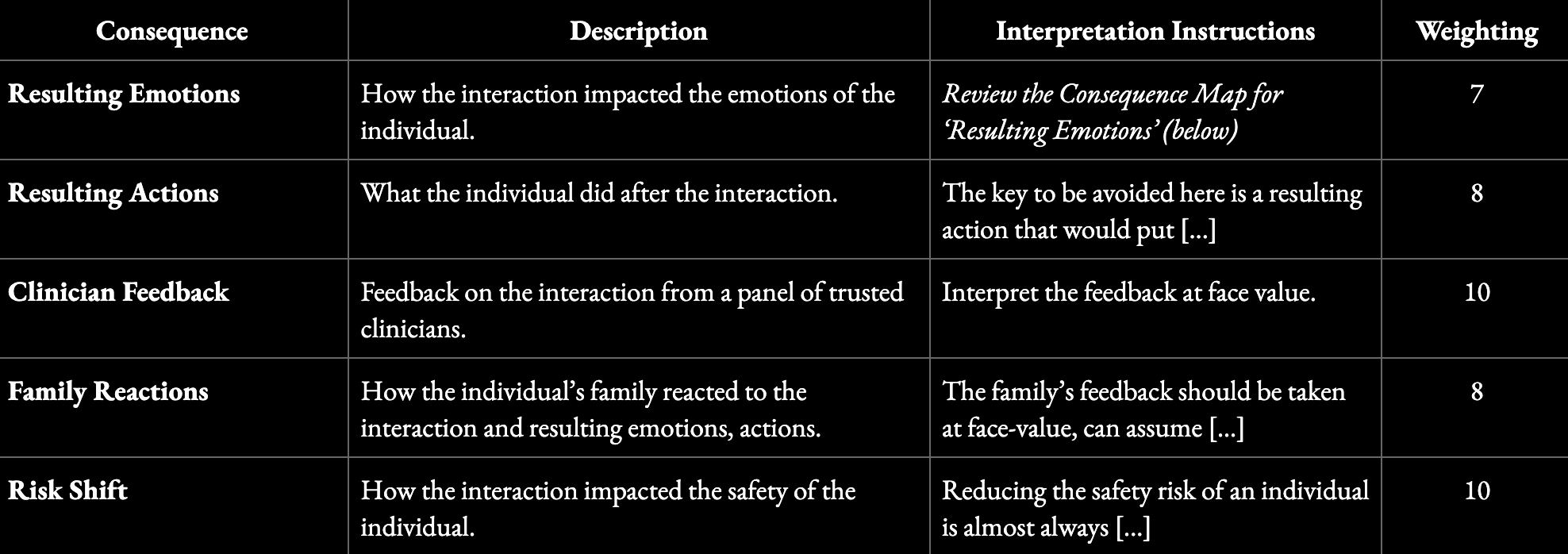
Each of these dimensions requires clear interpretation guidance and relative weighting. Sadness may be acceptable in some contexts. For example, a breakdown of ‘Resulting Emotions’ might look like this:
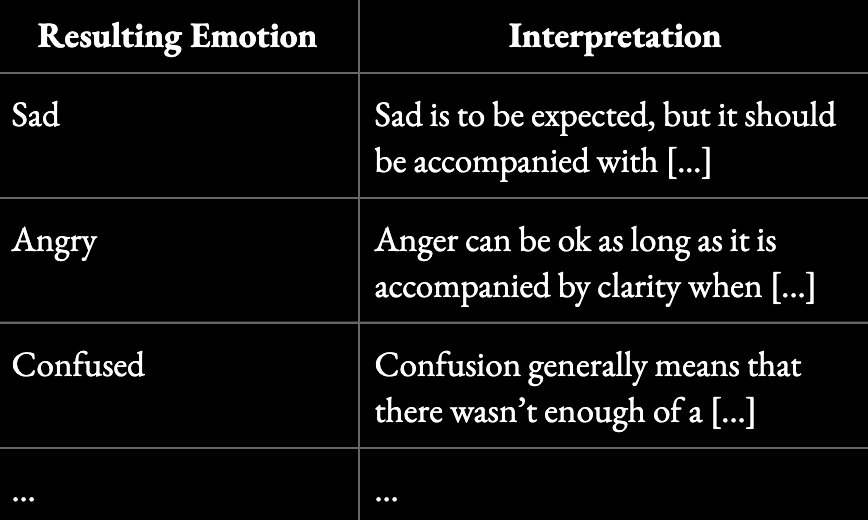
Our approach to consequence mapping is partly inspired by the 2025 paper “MoralReason: Generalizable Moral Decision Alignment for LLM Agents Using Reasoning-Level Reinforcement Learning,” which shows that reinforcing how models reason within a structured framework, leads to moral intuition that generalizes to new, unseen scenarios.
The goal is not to replace existing alignment techniques, but to give them better raw material. When models are trained on scenarios that reflect real stakes and labeled in terms of real outcomes, they can begin to develop something closer to intuition. Not just knowing which answers are allowed, but understanding why certain choices lead to better outcomes in the world.
To do this right, you need experts
To shape good intuition, the scenarios and consequences we define need to be deeply thought through. This is where it’s critical to engage trusted domain experts to help. In practice, Intuitive Alignment presents three core domain-specific challenges:
Selecting the right scenarios. Identifying a set of situations that is genuinely holistic and representative of real-world use, including edge cases, failure modes, and morally ambiguous moments.
Defining consequence maps. Explicitly specifying which outcomes matter in a given domain and how they should be interpreted. What signals indicate harm versus acceptable discomfort? What tradeoffs are tolerable? What outcomes dominate others?
Assessing consequences with judgment. Evaluating those outcomes in a way that reflects both empirical research and experienced human judgment.
Leveraging domain experts is the only way to address these challenges responsibly and credibly.
When AI needs judgment
AI has conquered technical and creative challenges remarkably well. It writes code, generates images, and summarizes data in ways we could never have imagined. But as these systems move beyond knowledge into domains requiring wisdom, we face a question that will define the future of this technology: How do we teach AI to have good judgment?
Consider citizens turning to AI for advice on how to vote in an upcoming election, or a teenager looking to AI for support during a mental health crisis. These moments can’t be solved with just facts and data, they require something more.
As we look ahead, the question isn't whether AI will shape our political discourse, guide our children, or influence our most important decisions. It’s whether we'll prepare it with the judgment these inevitable responsibilities demand.
Having worked on high-stakes AI systems across Facebook News, Instagram Youth Safety, and Meta's AI lab, I've seen how tricky it can be to train AI to have good judgment. Get this right, and AI could be a transformative force for good. Get it wrong, and we risk embedding mediocrity and harmful biases into systems that may shape humanity for generations.
But today's approach to training AI systems isn’t built for this.
Most AI development relies on "data labeling at scale": mobilizing thousands of contract workers to quickly evaluate model outputs. This works well for technical applications. But for subjective domains that require human judgement, we face a stark choice: Do we want AI trained by anyone available for contract work, or by the people humanity trusts as leading experts in their fields?
Having seen both approaches first-hand, I can tell you that the difference here is not just theoretical.
A junior psychologist working a side gig will evaluate mental health guidance differently than a researcher who has spent decades studying adolescent development. A graduate student labeling political content for cash brings a different perspective than a journalist who has covered conflicts across continents. In technical domains, these differences may not matter. In matters of judgment, they mean everything.
To bring high-caliber experts into the AI training loop, we need a new approach. This is what we’re building at Forum AI.
First, we need selectivity over scale in our networks. Instead of massive networks of annotators, we need smaller, curated networks of peer-reviewed experts: academics, industry veterans, and thought leaders whose judgment is trusted not just by their colleagues but by society at large.
Second, we need systems designed to scale the judgment of these elite experts for repetitive tasks like annotation. Their time is limited and expensive. By working closely with leading experts and institutions like Stanford Human-Centered AI, we've developed "expert-in-the-loop" AI systems that mirror expert annotation with high precision at scale: automating the repetitive while preserving the nuanced. Over time, we’ll have a large family of fine-tuned “expert judgement” models at our disposal.
Third, experts need a seat at the table to inform critical decisions. By automating repetitive tasks like annotation, we free our experts’ time to focus on higher-leverage work like defining benchmarks and discussing recommendations. Experts shouldn't be labeling thousands of responses in back rooms, they should sit at the table where decisions are made, alongside technical leaders.
At Forum AI, we bring world-leading experts—renowned academics, seasoned journalists, industry leaders—into the AI development process alongside technical teams. We help to produce benchmarks, human evaluations, LLM judges, and targeted training data that brings expert-level intelligence to AI systems when it matters most.
I believe that the future of AI will be defined not by the systems that can do the most things, but by those that can do the most important things well. This future demands we choose expertise over expedience.
Expert-in-the-loop
As AI grows more sophisticated, we need more sophisticated data to improve it.
Already today, we’re seeing declining demand for ‘sweatshop data’ and an increased need for data from skilled experts. Code samples from senior engineers, expert-annotated medical cases showing diagnostic thinking, and curated creative writing samples are now more valuable than bulk scraped content.
As this trend continues, it increasingly demands higher and higher levels of human expertise, creating a fundamental bottleneck where ever-more-specialized knowledge—not computing power or raw data—becomes the scarcest resource constraining progress.
We’ve found that this is especially true for subjective domains, such as news or sensitive topics, where careful, nuanced reasoning is required.
Unlike more technical fields where expertise can be more easily validated, these areas require human judgment calls about bias, context, cultural sensitivity, and ethical implications—the kind of sophisticated reasoning that should only come from seasoned domain specialists who understand not just what to think, but how to think responsibly about complex, contested issues.
For example, we've found that labeling for bias requires a nuanced and constantly evolving understanding of the political landscape. Within the conservative movement alone, there are diverse opinions on many topics, and understanding how to label data for these varying perspectives requires deep expertise in both politics and the specific subject matter.
The path forward: scaling expertise.
As AI demands higher and higher levels of human expertise, we need to get really good at scaling experts. Unlike today's approach of hiring thousands of people for millions of hours, highly skilled experts are scarce, expensive, and busy.
At Remark, we work with some of the world's most reputable experts to create data for the most challenging, sensitive topics. Throughout this work, we've identified several tactics for effectively scaling expert involvement.
Tactic 1 - Scenario Selection: Identifying the Optimal Scenarios for Generalization
We've found that AI can effectively scale expertise to adjacent scenarios when those scenarios are carefully chosen.
For example, in building our expert-in-the-loop source labeling system, we created a hierarchy of news topics—from broad verticals like geopolitics → subverticals like global conflicts → specific narratives like the Russia-Ukraine conflict → individual stories. We also mapped out the different label types such as bias, missing context, editorial significance, and source credibility.
This mapping of our domain allows us to systematically test where expert input generalizes well versus where it requires more specificity.
Through evals and qualitative checks, we discovered that expert input generalizes differently across levels. For example, bias judgments work well at the subvertical level, while editorial significance requires narrative-level specificity. This allows us to strategically optimize expert usage—we can gather bias labels more broadly at the subvertical level with fewer experts, but focus greater expert attention on editorial significance at more granular levels.
Over time, this structure enables surgical deployment of human expertise while leveraging AI generalization wherever possible.
Tactic 2 - Expert Selection: Surgically Involving the Right Experts at the Right Time
The second tactic is focused on using the right experts for the right scenarios.
Starting with our domain structures from above, we can map experts to different specialties based on where they uniquely demonstrate the greatest accuracy and knowledge. For instance, if one expert excels at labeling editorial significance for global conflict sources, we focus their efforts there rather than areas where they're less effective.
But surgical involvement goes further than basic mapping. We build detailed internal profiles of our experts including work history, published topics, life experiences, and affiliations. For example, when we're looking to gather insights from experts to generate net new content as part of our retrieval or training data offerings, we use LLMs to search through these profiles and identify where each expert can provide uniquely valuable input.
Interestingly, this approach has allowed us to leverage experts in more ways than we would have expected. While we might map an expert to editorial significance for global conflicts based on their apparent expertise, our detailed profiles revealed we could also leverage Economics experts to analyze trade implications in geopolitical stories like the Trump/Putin meeting.
Tactic 3 - Rubrics for Everything
The third tactic involves creating detailed rubrics that capture expert reasoning and enable AI systems to generalize expert judgment to certain specific scenarios. Expert-established rubrics can be an effective tool for instructing AI to think like domain specialists in targeted contexts.
For example, rubrics for evaluating an AI System’s output can scale LLM-as-a-judge evaluations, allowing AI to apply expert-level judgment across thousands of examples rather than requiring individual expert review. We work with experts to create rubrics for specific verticals and subverticals and then use that to inform an LLM-as-a-judge for scaled evals.
This approach is also emerging in training methodologies, where expert rubrics function as sophisticated reward models that guide AI behavior during fine-tuning.
The future of AI progress increasingly depends on our ability to capture and scale the world's best human expertise. As models become more sophisticated, the bottleneck shifts from raw computational power to accessing the nuanced judgment and specialized knowledge that only true experts possess.
The tactics we've outlined—strategic scenario selection, surgical expert involvement, and comprehensive rubric development—are probably just the beginning of what's possible. At Remark, we're continuing to refine these approaches as we work with leading experts across domains.
If you're building AI systems that need expert-level training data, or if you're interested in implementing these expert-scaling tactics in your own work, we'd love to hear from you. Reach out to discuss how we can help unlock the expertise your AI systems need to reach their full potential.
From chaos to clarity
For the past several years, I’ve worked at the crossroads of news, AI, and social media; leading trust and safety efforts at Facebook, Instagram, and Meta AI, and advising smaller companies grappling with these same challenges. I've tackled issues ranging from COVID misinformation to racism, election integrity, and global conflicts at billion-user scale.
It’s no surprise to me that AI is already transforming how we navigate news and sensitive topics. The appeal is obvious. Faced with an endless stream of articles, social media posts, and claims, we've embraced AI as our filter: a single source of truth cutting through information chaos. No bylines, comment threads, or sourcing to worry about, just clean, seemingly authoritative answers to complex questions.
It feels like exactly the right solution at exactly the right time.
But we're not solving our information crisis. We're masking it. The fundamental challenge hasn't disappeared, it's simply been transferred to machines that are even less equipped to handle it than we are. AI systems need to parse the same chaotic mix of perspectives, the same incomplete coverage, the same conflicting narratives that overwhelm human readers.
Consider what happens when an AI system encounters competing narratives about economic policy, international conflicts, or public health measures. We can instruct the AI to "be balanced and accurate," but without proper tools, these commands are meaningless. It's like asking someone to cook a gourmet meal blindfolded with no recipe books.
In practice, this leads to inadequate outputs: while AI systems excel at code and problem solving, they make errors when talking about news over 50% of the time.
AI systems need maps, not just directions.
The path forward requires translating our complex news ecosystem for AI. We can’t just feed news sources to the AI and hope it does a good job, we have to give it the context it needs to prioritize, interpret, and talk about that news. But how do we do this? We could cross our fingers and let AI make these decisions itself? We could trust a private company to do this in a black box?
The right answer is to empower credible, trusted experts to design this future.
We need economists explaining how they evaluate policy coverage. We need regional specialists identifying when translation choices obscure cultural context. We need scientists distinguishing between preliminary findings and robust consensus or between industry-funded research and independent studies.
→ This information can help us build “News Labelers” that add the necessary context to sources so that AI systems can select, prioritize, and interpret them.
We need experts to determine how AI systems should talk about the news. When should they acknowledge uncertainty? How do they distinguish fact from opinion? What terminology should be used or avoided? How should this differ across economics, geopolitics, and sports?
→ This information can help us set “Communication Standards” for how we instruct AI systems to communicate accurately and transparently about news.
We also need domain experts to tell us what “good” looks like. What makes an answer better or worse? What is the relative importance of depth vs. clarity across topics? How does this differ across verticals?
→ This information can help us establish “Evaluation Criteria” that the industry can use to measure and improve upon our systems. We can even use this to establish public benchmarks rooted in expertise.
While the prospect of AI transforming news feels threatening, it's actually our best opportunity to fix information problems that predate these technologies. Today we're drowning in conflicting sources, trapped in echo chambers, and overwhelmed by the volume of information demanding our attention.
If we can work with domain experts to build the right foundation—including News Labelers that provide crucial context, Communication Standards that ensure transparent communication, and Evaluation Criteria rooted in genuine expertise—we can create AI systems that genuinely improve upon our news ecosystem rather than simply automating our confusion.